

In Kubernetes, managing scaling efficiently is crucial for maintaining application performance and optimizing resource utilization. In this article, we’ll delve into the fundamental concepts of auto-scaling, focusing on Horizontal Pod Autoscaling (HPA) and Vertical Pod Autoscaling (VPA), and explore how these mechanisms can help you manage your Kubernetes workloads effectively.
What is Scaling in Kubernetes?
Scaling refers to adjusting your resources to meet the demand for your applications. In Kubernetes, scaling can be performed manually or automatically. Initially, you might manually adjust the number of replicas in a deployment or increase the number of nodes in your cluster. However, in a production environment, especially with thousands of pods, manual scaling becomes impractical and inefficient.
This is where auto-scaling comes into play. Auto-scaling dynamically adjusts the resources based on the workload, ensuring that your application performs optimally without manual intervention.
Types of Auto-Scaling
Kubernetes offers several auto-scaling mechanisms to help manage your workloads efficiently. These mechanisms adjust resources dynamically based on various metrics and conditions, ensuring optimal performance and resource utilization. Let's now take a look at two primary types of auto-scaling in Kubernetes in greater detail: Horizontal Pod Autoscaling (HPA) and Vertical Pod Autoscaling (VPA).
1. Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaling is about scaling the number of pod replicas based on resource utilization. For example, if you have a deployment with a single pod and the demand increases (more users accessing the application), HPA will automatically add more replicas of the pod.
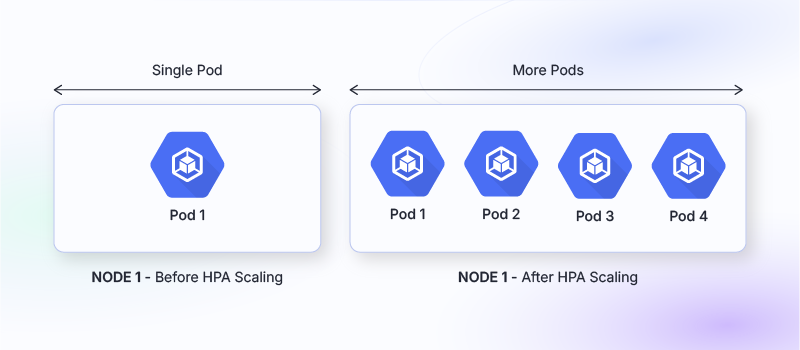
Example: Suppose you have a deployment running a web application with one pod. As traffic increases, the CPU utilization of the pod rises. HPA detects this and adds more pods to handle the increased load, ensuring consistent performance.
1. Purpose:
- HPA adjusts the number of pod replicas in a deployment or replica set based on observed CPU utilization or other select metrics.
2. How It Works:
- Metrics Collection: HPA monitors metrics like CPU utilization or custom metrics (e.g., memory usage, and request rate). Metrics are collected using the Kubernetes Metrics Server or Prometheus.
- Scaling Algorithm: It calculates the average metric value across pods and compares it to a target value set in the HPA configuration. If the actual value deviates from the target, HPA scales the number of pods up or down accordingly.
3. Configuration:
- Target Utilization: Set a target metric value (e.g., 50% CPU utilization).
- Min/Max Replicas: Define the minimum and maximum number of pod replicas to prevent scaling too low or too high.
- Example YAML:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 504. Advantages:
- Dynamic Adjustment: Automatically scales the number of pods based on load, ensuring efficient resource usage.
- Cost Efficiency: Reduces operational costs by scaling down resources during low-traffic periods.
5. Limitations:
- Granularity: Scaling decisions are made based on average metrics, which might not account for individual pod performance variances.
- Cold Start: New pods might experience a delay in becoming fully operational, affecting overall performance temporarily.
2. Vertical Pod Autoscaling (VPA)
Vertical Pod Autoscaling adjusts the resource requests and limits of a pod based on its current usage. Unlike HPA, which scales the number of pods, VPA resizes the resources allocated to a single pod.
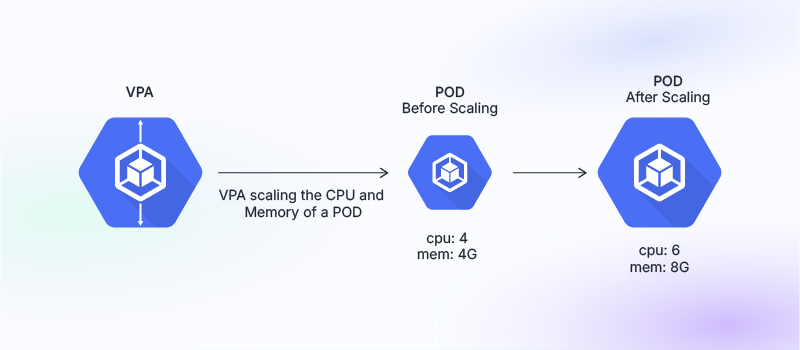
Example: Imagine a pod initially configured with 4 CPU and 4GB of memory. If it starts using significantly more resources due to increased demand, VPA will adjust the pod’s resource allocation to 6 CPUs and 8GB of memory. The pod will be restarted with these new settings to accommodate the increased load.
1. Purpose:
- VPA adjusts the CPU and memory resources allocated to individual pods based on their usage patterns, without changing the number of pod replicas.
2. How It Works:
- Resource Monitoring: VPA monitors resource usage of pods over time and makes recommendations or applies changes to the pod resource requests and limits.
- Scaling Algorithm: It uses historical data to predict future resource needs and adjusts the pod’s resource requests and limits accordingly.
3. Configuration:
- Target Resource Usage: Define resource utilization targets for CPU and memory.
- Update Policy: Configure whether VPA should automatically apply resource recommendations or only provide suggestions.
- Example YAML:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
updatePolicy:
updateMode: "Auto" # or "Off" to only get recommendations4. Advantages:
- Optimal Resource Allocation: Ensures that pods have adequate resources based on their actual needs, avoiding under or over-provisioning.
- Performance Improvement: Helps in maintaining performance consistency by adjusting resources to meet the pod’s demand.
5. Limitations:
- Pod Restarts: Applying resource changes typically requires restarting the pods, which can cause brief interruptions.
- Complexity: Managing VPA alongside HPA can be complex, as they might work against each other (e.g., HPA might scale out while VPA resizes resources).
Horizontal vs. Vertical Auto-Scaling
- Horizontal Auto-Scaling: Adds or removes pod replicas based on load. It’s useful when you need to handle increased traffic by scaling out your application.
- Vertical Auto-Scaling: Adjusts the resources of existing pods. It’s beneficial when the resource needs of a pod change over time but doesn’t require adding more replicas.
Additional Auto-Scaling Concepts
In addition to HPA and VPA, Kubernetes provides several advanced auto-scaling techniques. Let's briefly take a look at some of them.
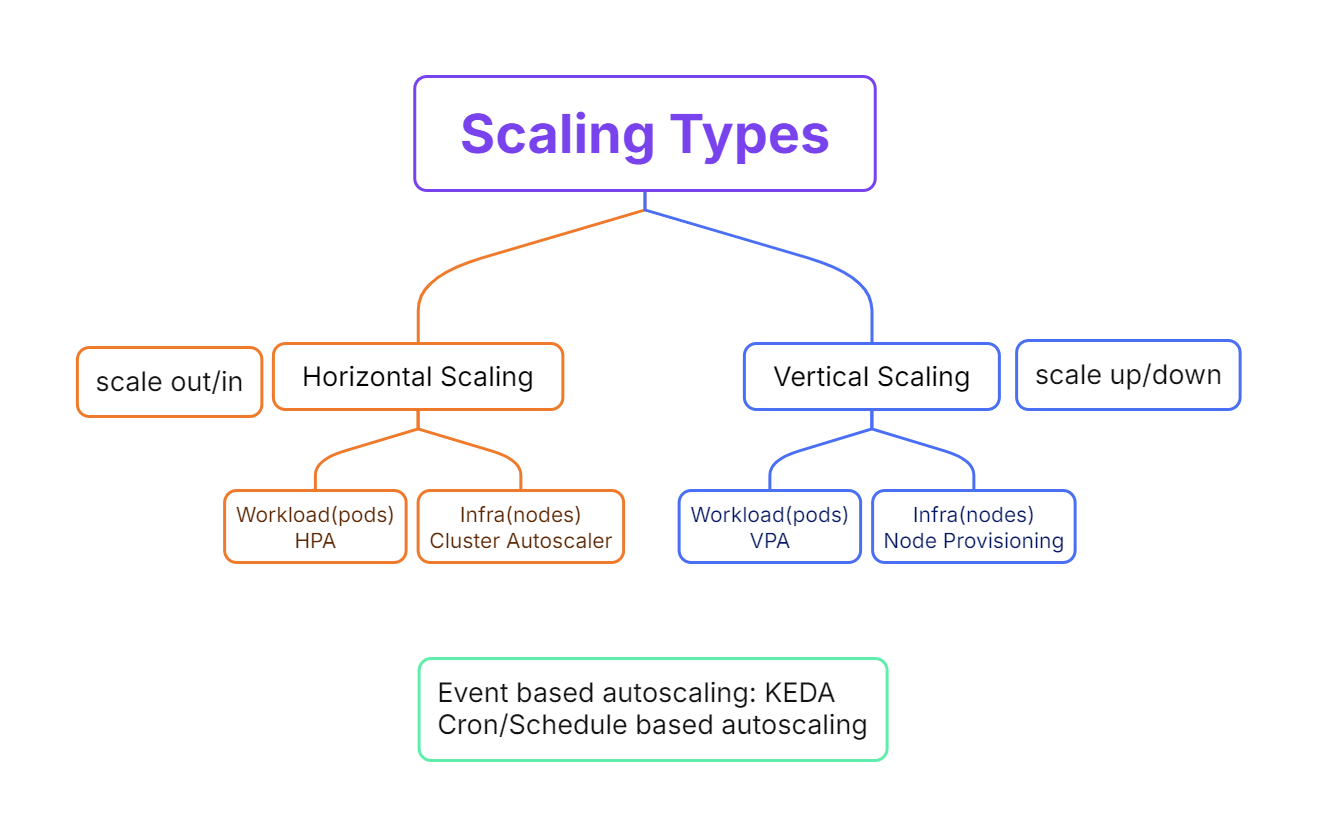
Cluster Autoscaler
Cluster Autoscaler manages the scaling of cluster nodes based on your workloads' resource demands. It works with HPA and VPA by adding or removing nodes from the cluster as needed.
Event-Based Autoscaling
Event-based autoscaling responds to specific events or conditions, such as an increased number of error responses. Tools like KEDA (Kubernetes Event-driven Autoscaler) can be used for this purpose.
Scheduled Autoscaling
Scheduled autoscaling allows you to scale your workloads based on a schedule, such as increasing resources during peak hours and reducing them during off-peak times.
Conclusion
Understanding and implementing auto-scaling mechanisms like HPA and VPA in Kubernetes can significantly enhance your application’s performance and resource efficiency. While HPA and VPA cover the fundamental aspects of auto-scaling, additional tools and concepts such as Cluster Autoscaler and event-based autoscaling can further optimize your Kubernetes environment. Mastering these concepts will not only help you in real-world scenarios but also give you a deeper insight into managing Kubernetes clusters effectively.

